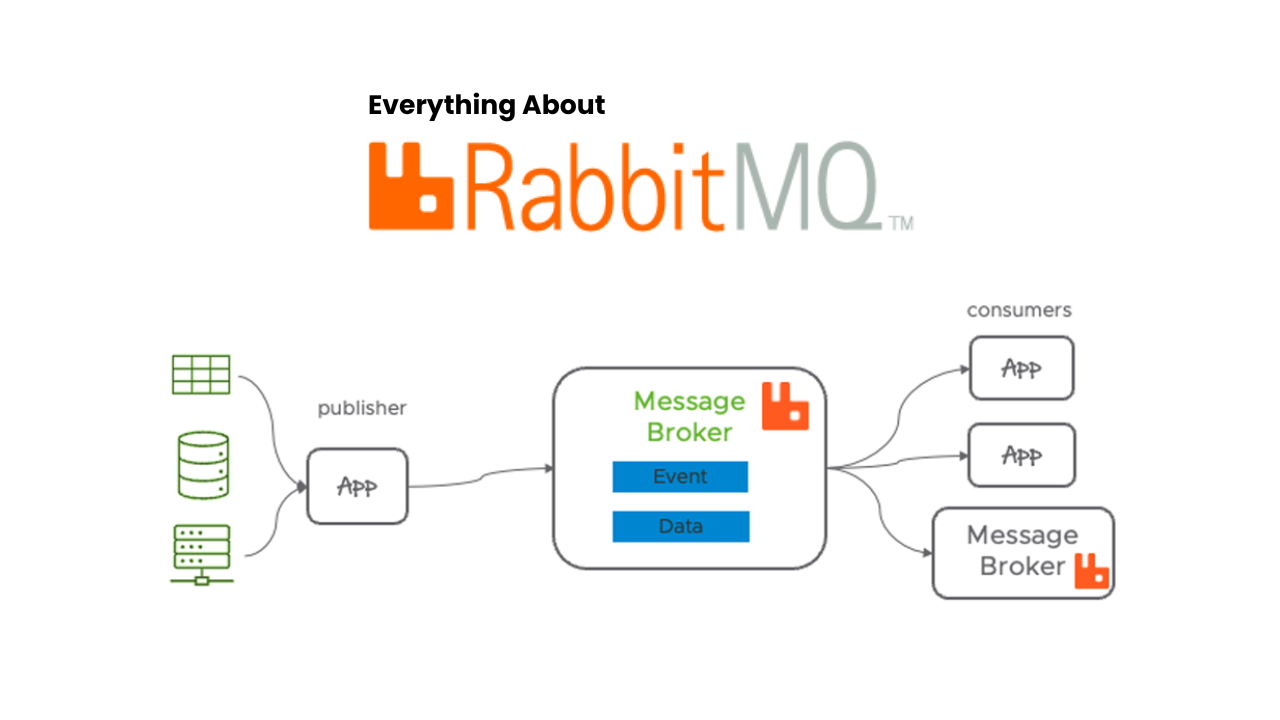
What is RabbitMQ?
RabbitMQ is an open-source message broker that facilitates communication between different components of a system by using message queues. Enables Asynchronous Programming i.e. it allows messages to be queued for later processing, ideal for long-running or blocking tasks, letting web servers respond quickly to requests while RabbitMQ stores and forwards messages to consumers when ready.
Why RabbitMQ?
- Reliable and Open Source
- since 2007
- strong community and highly active core team that produce additional features, improvements and handy plugins.
- Supports several standardized protocols such as AMQP 0-9-1, AMQP 1-0, MQTT, STOMP, STOMP over WebSockets, MQTT over WebSockets.
- Used by a large number of companies within various industries and is used and trusted by large companies (Zalando, WeWork, Wunderlist, Bloomberg, and more). All relying on a microservice based architecture.
- User-Friendly
- It is easy to tweak the configurations to suit the intended purpose.
- RabbitMQ is written in Erlang and is the world’s most deployed open-source message broker, meaning that it’s a well-tested, robust broker.
- Highly Scalable
- Your only have to maintain the producers and the consumers sending and receiveing messages to/from the queue. Under heavy load, if the queue grows larger, the standard reaction is to add more consumers and parallelize the work. This is a simple and effective method of scaling.
- You can also allow the broker to scale (add more resources through CPU/disk/memory), to be able to handle more messages in the queue. But remember that RabbitMQ works fastest with short queues.
In this article, we will consider you are using rabbitmq over amqp 0-9-1 protocol. It is unlikely that RabbitMQ will deviate from AMQP 0.9.1. Version 1.0 of the protocol was released on October 30, 2011 but has not gained widespread support from developers.
Architecture Diagram of Rabbitmq
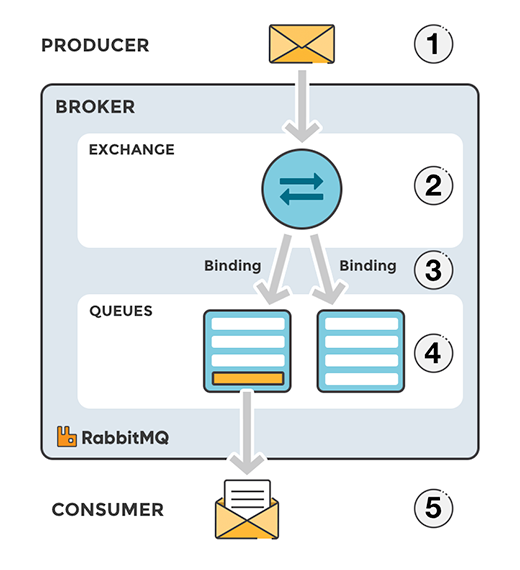
Messages are not published directly to a queue. Instead, the producer sends messages to an exchange. Exchanges are message routing agents, defined by the virtual host within RabbitMQ. An exchange is responsible for routing the messages to different queues with the help of header attributes, bindings, and routing keys.
A binding is a "link" that you set up to bind a queue to an exchange.
The routing key is a message attribute the exchange looks at when deciding how to route the message to queues (depending on exchange type).
Understanding each component in depth and its configuration
Connection
AMQP 0-9-1 provides a way for connections to multiplex over a single TCP connection. That means an application can open multiple "lightweight connections" called channels on a single connection. AMQP 0-9-1 clients open one or more channels after connecting and perform protocol operations (manage topology, publish, consume) on the channels.
Connection Lifecycle
In order for a client to interact with RabbitMQ it must first open a connection. This process involves a number of steps:
- Application configures the client library it uses to use a certain connection endpoint (e.g. hostname and port)
- The library resolves the hostname to one or more IP addresses
- The library opens a TCP connection to the target IP address and port
- After the server has accepted the TCP connection, protocol-specific negotiation procedure is performed
- The server then authenticates the client
- The client now can perform operations, each of which involves an authorisation check by the server.
- The client retains the connections for as long as it needs to communicate with RabbitMQ
This flow doesn't change significantly from protocol to protocol but there are minor differences
Parameters while opening a connection(may vary according to client library used)
host- Hostname or IP Address to connect toport- TCP port to connect tovirtual_host- RabbitMQ virtual host to usecredentials- auth credentialschannel_max- Maximum number of channels to allowframe_max- The maximum byte size for an AMQP frameheartbeat- Controls AMQP heartbeat timeout negotiation during connection tuning. An integer value always overrides the value proposed by broker. Use 0 to deactivate heartbeats and None to always accept the broker's proposal. If a callable is given, it will be called with the connection instance and the heartbeat timeout proposed by broker as its arguments. The callback should return a non-negative integer that will be used to override the broker's proposal.ssl_options- None for plaintext orpika.SSLOptionsinstance for SSL/TLS. Defaults to None.connection_attempts- Maximum number of retry attemptsretry_delay- Time to wait in seconds, before the nextsocket_timeout- Positive socket connect timeout in seconds.stack_timeout- Positive full protocol stack (TCP/[SSL]/AMQP) bring-up timeout in seconds. It's recommended to set this value higher thansocket_timeout.blocked_connection_timeout- If not None, the value is a non-negative timeout, in seconds, for the connection to remain blocked (triggered by Connection.Blocked from broker); if the timeout expires before connection becomes unblocked, the connection will be torn down, triggering the adapter-specific mechanism for informing client app about the closed connection: passingConnectionBlockedTimeoutexception to on_close_callback in asynchronous adapters or raising it inBlockingConnection.client_properties- None or dict of client properties used to override the fields in the default client properties reported to RabbitMQ viaConnection.StartOkmethod.tcp_options- None or a dict of TCP options to set for socket
Parameters while deriving a channel for the connection
channel_number- Must be non-zero if you would like to specify but it is recommended that you let Client Library manage the channel numbers.
Note: Channel created on thread should not be shared among multiple threads in an application. This is because if 2 threads at application layer try to communicate with the next layers with the same channel id concurrently, it might result in some errors. Also, one more point to notice here, although you have multiple channels which can communicate to Transport Layer concurrently but still since they are using a common TCP connection, bottleneck is still present over Transport Layer(TCP will not allow packet to move to further layers, till it has received ACK for the previous packet)
Recovery from connection failures
Network connection between clients and RabbitMQ nodes can fail. How applications handle such failures directly contributes to the data safety of the overall system.
Several RabbitMQ clients support automatic recovery of connections and topology (queues, exchanges, bindings, and consumers): Java, .NET, Bunny are some examples.
Other clients do not provide automatic recovery as a feature but do provide examples of how application developers can implement recovery.
The automatic recovery process for many applications follows the following steps:
- Reconnect to a reachable node
- Restore connection listeners
- Re-open channels
- Restore channel listeners
- Restore channel basic.qos setting, publisher confirms and transaction settings
After connections and channels are recovered, topology recovery can start. Topology recovery includes the following actions, performed for every channel [the steps mentioned below discussed in detail later]
- Re-declare exchanges (except for predefined ones)
- Re-declare queues
- Recover all bindings
- Recover all consumers
Exchange
Parameters you can set while creating/declaring exchange(can vary depending on the library used to interact with rabbitmq)
durable- Durable exchanges survive server restarts and last until they are explicitly deletedtemporary- Temporary exchanges exist until RabbitMQ is shut down.auto-delete- Auto-deleted exchanges are removed once the last bound object is unbound from the exchange.exchange_type-- Options - direct, fanout, headers, topic
arguments- Custom key/value pair arguments for the exchangeinternal- Options - True, False
- Can only be published to by other exchanges
Types
- Direct Exchange
- delivers messages to queues based on a message routing key.
- routing key is a message attribute added to the message header by the producer. Think of the routing key as an "address" that the exchange is using to decide how to route the message. A message goes to the queue(s) with the binding key that exactly matches the routing key of the message.
- useful to distinguish messages published to the same exchange using a simple string identifier.
- Default Exchange
- The default exchange is a pre-declared direct exchange with no name, usually referred by an empty string. When you use default exchange, your message is delivered to the queue with a name equal to the routing key of the message. Every queue is automatically bound to the default exchange with a routing key which is the same as the queue name.****
- Topic Exchange
- route messages to queues based on wildcard matches between the routing key and the routing pattern, which is specified by the queue binding
- Messages are routed to one or many queues based on a matching between a message routing key and this pattern.
- The routing key must be a list of words, delimited by a period (.). Examples are agreements.us and agreements.eu.stockholm which in this case identifies agreements that are set up for a company with offices in lots of different locations.
- The routing patterns may contain an asterisk (“”) to match a word in a specific position of the routing key (e.g., a routing pattern of "agreements...b." only match routing keys where the first word is "agreements" and the fourth word is "b").
- A pound symbol (“#”) indicates a match of zero or more words (e.g., a routing pattern of "agreements.eu.berlin.#" matches any routing keys beginning with "agreements.eu.berlin").
- The consumers indicate which topics they are interested in (like subscribing to a feed for an individual tag). The consumer creates a queue and sets up a binding with a given routing pattern to the exchange. All messages with a routing key that match the routing pattern are routed to the queue and stay there until the consumer consumes the message.
- Fanout Exchange
- copies and routes a received message to all queues that are bound to it regardless of routing keys or pattern matching as with direct and topic exchanges.
- The keys provided will simply be ignored.
- useful when the same message needs to be sent to one or more queues with consumers who may process the same message in different ways.
- Headers Exchange
- routes messages based on arguments containing headers and optional values.
- very similar to topic exchanges, but route messages based on header values instead of routing keys
- A message matches if the value of the header equals the value specified upon binding.
- A special argument named "x-match", added in the binding between exchange and queue, specifies if all headers must match or just one
- "x-match" property can have two different values: "any" or "all", where "all" is the default value. A value of "all" means all header pairs (key, value) must match, while value of "any" means at least one of the header pairs must match.
- Headers can be constructed using a wider range of data types, integer or hash for example, instead of a string. The headers exchange type (used with the binding argument "any") is useful for directing messages which contain a subset of known (unordered) criteria.
- Dead Letter Exchange(or Alternate Exchange)
- If no matching queue can be found for the message, the message is silently dropped(mandatory field set to False) or returned to publisher(if mandatory field is set to True while publishing message[
discussed later]). RabbitMQ provides an AMQP extension known as the "Dead Letter Exchange", which provides the functionality to capture messages that are not deliverable.(in case mandatory field is set to False) - How to create?
- Can be defined by clients using policies(recommended)
- Or using optional exchange arguments at exchange declaration
- In case both policy and argument specify an Alternate Exchange, the one specified in arguments overrules the one specified in policy
- Whenever an exchange with a configured AE cannot route a message to any queue, it publishes the message to the specified AE instead. If that AE does not exist then a warning is logged. If an AE cannot route a message, it in turn publishes the message to its AE, if it has one configured. This process continues until either the message is successfully routed, the end of the chain of AEs is reached, or an AE is encountered which has already attempted to route the message.
- For configuration - check https://www.rabbitmq.com/ae.html
- If no matching queue can be found for the message, the message is silently dropped(mandatory field set to False) or returned to publisher(if mandatory field is set to True while publishing message[
Queue
Parameters you can set while declaring queue
name- unique queue namedurable- If set to true, queue survive reboots of the broker- options - True/False
exclusive- can be used only by its declaring connection(queue deleted when the connection is closed)- options - True/False
auto-delete- Delete queue after consumer cancels or disconnects- options - True/False
arguments- Custom key/value arguments for the queue
Binding a queue to an exchange
name- name of queue to bindexchange- The source exchange to bind torouting_key- The routing key to bind onarguments- Custom key/value pair arguments for the binding
Unbinding queue from an exchange
- You can set same parameters as above while binding
Virtual Hosts
To make it possible for a single broker to host multiple isolated "environments" (groups of users, exchanges, queues and so on), AMQP 0-9-1 includes the concept of virtual hosts (vhosts). They are similar to virtual hosts used by many popular Web servers and provide completely isolated environments in which AMQP entities live. Protocol clients specify what vhosts they want to use during connection negotiation.
Consumers
Consumer subscribes to listen messages on a queue(by creating a new one or connecting to existing one), and then its your choice if you want consumer to acknowledge the message by send ack to the broker.
If you have setup this acknowledgement to make system more reliable(of course this will decrease performance/throughput but its worth it in case you want to assure reliability), queue will remove the message from queue only after getting the acknowledgement from the consumer. In case if broker couldn’t receive acknowledgment due to packet drop/connection loss/system shutdown, queue will again try to push the message to available consumers after waiting for certain duration.(try to make consumer message processing tasks idempotent in this case)
Basic steps while setting up a consumer
- Make a connection
- Get a channel from connection
- Declare queue(if its not setup)
- set
qos(quality of service) over channel-
prefetch_size- This field specifies the prefetch window size. The server will send a message in advance if it is equal to or smaller in size than the available prefetch size (and also falls into other prefetch limits). May be set to zero, meaning "no specific limit", although other prefetch limits may still apply. -
prefetch_count- Specifies a prefetch window in terms of whole messages. This field may be used in combination with the prefetch-size field; a message will only be sent in advance if both prefetch windows (and those at the channel and connection level) allow it. -
global_qos- Should the QoS apply to all channels on the connection.
Note: Both
prefetch-sizeandprefetch-countignored whenno-ackset to true (that is how auto-ack functionality called in RabbitMQ and in AMQP docs), messages will be sent to client one-by-one and removed from queue after successful sending. -
Prameters
queue- The queue from which to consumeon_message_callback- function to run after message is consumed from queueauto_ack- Options - True/False
- if set to True, automatic acknowledgement mode will be used. This corresponds with the 'no_ack' parameter in the basic.consume AMQP 0.9.1 method
Note:
- if consumers's TCP connection or channel is closed before successful delivery, the message sent by the server will be lost. Therefore, automatic message acknowledgement should be considered unsafe and not suitable for all workloads.
- Another thing that's important to consider when using automatic acknowledgement mode is consumer overload. Manual acknowledgement mode is typically used with a bounded channel prefetch which limits the number of outstanding ("in progress") deliveries on a channel. With automatic acknowledgements, however, there is no such limit by definition. Consumers therefore can be overwhelmed by the rate of deliveries, potentially accumulating a backlog in memory and running out of heap or getting their process terminated by the OS. Some client libraries will apply TCP back pressure (stop reading from the socket until the backlog of unprocessed deliveries drops beyond a certain limit). Automatic acknowledgement mode is therefore only recommended for consumers that can process deliveries efficiently and at a steady rate.
exclusive- If set to True, Don't allow other consumers on the queueconsumer_tag- You may specify your own consumer tag; if left empty, a consumer tag will be generated automaticallyarguments- Custom key/value pair arguments for the consumer
Understanding delivery tags
When a consumer (subscription) is registered, messages will be delivered (pushed) by RabbitMQ using the basic.deliver method. The method carries a delivery tag, which uniquely identifies the delivery on a channel. Delivery tags are therefore scoped per channel.
Delivery tags are monotonically growing positive integers and are presented as such by client libraries. Client library methods that acknowledge deliveries take a delivery tag as an argument.
Because delivery tags are scoped per channel, deliveries must be acknowledged on the same channel they were received on. Acknowledging on a different channel will result in an "unknown delivery tag" protocol exception and close the channel.
Acknowledging Multiple Deliveries at Once
Instead of acknowledging messages one by one, consumer can also process a batch of messages and acknowledge them in a single go(for this consumer will have to keep a track of messages it has processed, in case this data is lost, it will result in requeueing of messages) to reduce network traffic.
This is done by setting the multiple field to true while acknowledging. When the multiple field is set to true, RabbitMQ will acknowledge all outstanding delivery tags up to and including the tag specified in the acknowledgement. Like everything else related to acknowledgements, this is scoped per channel
Ex. given that there are delivery tags 5, 6, 7, and 8 unacknowledged on channel Ch, when an acknowledgement frame arrives on that channel with delivery_tag set to 8 and multiple set to true, all tags from 5 to 8 will be acknowledged. If multiple was set to false, deliveries 5, 6, and 7 would still be unacknowledged.
Negative Acknowledgement and Requeuing of Deliveries
Consumer can also reject a message which means delivery wasn't processed but consumer wants that message to be either discarded or send to Alternate Exchange or requeue. This can be done by 2 protocol methods
basic.reject- only one message can be rejected at a time(limitation)basic.nack- possible to reject or requeue multiple messages at once using this method by setting multiple field
Understanding requeue field
-
If set to
True- Message will be requeued to the queue and it will be placed to its original position in its queue, if possible. If not (due to concurrent deliveries and acknowledgements from other consumers when multiple consumers share a queue), the message will be requeued to a position closer to queue head.Requeued messages may be immediately ready for redelivery depending on their position in the queue and the prefetch value used by the channels with active consumers. This means that if all consumers requeue because they cannot process a delivery due to a transient condition, they will create a requeue/redelivery loop. Such loops can be costly in terms of network bandwidth and CPU resources. Consumer implementations can track the number of redeliveries and reject messages for good (discard them) or schedule requeueing after a delay.
Redeliveries will have a special boolean property,
redeliver, set to true by RabbitMQ. For first time deliveries it will be set to false. Note that a consumer can receive a message that was previously delivered to another consumer. -
If set to
False, the message will be routed to a Dead Letter Exchange if it is configured, otherwise it will be discarded.
Publisher
Steps generally followed by publisher/producer
- Make a connection
- Get a channel from connection, one connection can be multiplexed into multiple channels. (You can use a common connection all over your application, you can create multiple channels for performing different kinds of publishment, but it totally depends on your strategy)
- Publish Message
Parameters you can set while publishing a message to rabbitmq
exchange- The exchange to publish torouting_key- The routing key to bind onbody- The message body; empty string if no bodyproperties-- message properties
- You can set various properties like delivery_mode(Persistent[message will be saved to disk in case queue is durable, this will prevent message to be lost in case of broker restart], Transient), priority, headers(for headers exchange)
- Saving message to disk (in case of Persistent message) can even happen after the message has been consumed by consumer
Edge case- What if broker crashes before saving message to disk in case message is persistent and queue is durable and you can’t afford that? → Solution isPublisher Confirmsor usingTransactional Channels[Discussed Later]
mandatory-- If set to True, incase message is unroutable, it will be returned to publisher
- Prerequisite - You should have setup a return message handler function
Using standard AMQP 0-9-1, the only way to guarantee that a message isn't lost is by using transactions -- make the channel transactional then for each message or set of messages publish, commit. In this case, transactions are unnecessarily heavyweight and decrease throughput by a factor of 250. [Transactional Channels discussed later]
To remedy this, a confirmation mechanism was introduced. It mimics the consumer acknowledgements mechanism already present in the protocol.
Publisher Confirms
To enable confirms, a client sends the confirm.select method. Depending on whether no-wait was set or not, the broker may respond with a confirm.select-ok. Once the confirm.select method is used on a channel, it is said to be in confirm mode. A transactional channel cannot be put into confirm mode and once a channel is in confirm mode, it cannot be made transactional.
Once a channel is in confirm mode, both the broker and the client count messages (counting starts at 1 on the first confirm.select). The broker then confirms messages as it handles them by sending a basic.ack on the same channel. The delivery-tag field contains the sequence number of the confirmed message. The broker may also set the multiple field in basic.ack to indicate that all messages up to and including the one with the sequence number have been handled.
In order to track which messages are confirmed by broker, you can store the messages published in a map kind of data structure(key value pairs, key- message sequence no., value - message body)
The sequence number can be obtained with Channel#getNextPublishSeqNo() before publishing
Once the message is confirmed(message ack is received on publisher), you can remove the message for this map.
For routable messages, the basic.ack is sent when a message has been accepted by all the queues. For persistent messages routed to durable queues, this means persisting to disk.
basic.ack for a persistent message routed to a durable queue will be sent after persisting the message to disk. The RabbitMQ message store persists messages to disk in batches after an interval (a few hundred milliseconds) to minimise the number of fsync(2) calls, or when a queue is idle.
This means that under a constant load, latency for basic.ack can reach a few hundred milliseconds. To improve throughput, applications are strongly advised to process acknowledgements asynchronously (as a stream) or publish batches of messages and wait for outstanding confirms. The exact API for this varies between client libraries.
For unroutable messages, the broker will issue a confirm once the exchange verifies a message won't route to any queue (returns an empty list of queues). If the message is also published as mandatory, the basic.return is sent to the client before basic.ack. The same is true for negative acknowledgements (basic.nack).
Edge Cases
- So, in case you have set mandatory as true and also enabled publisher confirm, then once publisher have got the returned unroutable message, it can either requeue or discard it (incase this packet is lost due to any reason, then since you have enabled publisher confirm, you may get acknowledgement later and this point you can check if action was not taken earlier now requeue or discard it[by taking reference from the map data structure you are maintaining for tracking publish messages in publisher]).
- Also its possible that you may loose ack packet from broker, if that happens publisher will wait for certain duration, after which it can check if action was taken before when unroutable message was returned(if action was not taken or no message was returned due to packet loss or mandatory was set to False, publisher may take action now [by taking reference from the map data structure you are maintaining for tracking publish messages in publisher])
- Also, its possible that before the message acknowledgement from broker is received, publisher resets or restarts, and in case Ack packet is lost due to packet loss, this will lead to a complete loss of message. In case you can’t afford message loss and want complete reliability, you will have to track the messages published by storing it in reliable memory space.(first storing it in reliable memory space and then publishing to broker)
Techniques to implement Publisher Confirms(check this article for more detailed explanation - https://www.rabbitmq.com/tutorials/tutorial-seven-java.html)
- publishing messages individually, waiting for the confirmation synchronously: simple, but very limited throughput.
- publishing messages in batch, waiting for the confirmation synchronously for a batch: simple, reasonable throughput, but hard to reason about when something goes wrong.
- asynchronous handling: best performance and use of resources, good control in case of error, but can be involved to implement correctly.[Recommended]
Transactions in RabbitMQ
- Every transaction commit forces working thread to wait the end of commit. This end of commit can be, for example, the moment when all concerned queues accept sent message. Additionally, if the message is persistent, each published transaction requires fsync modified data. Simply speaking, it writes data on disk.
- decrease throughput by a factor of 250
Exception Handling in Publisher
-
A network I/O exception due to a failed write or timeout
-
can occur immediately during a write or with a certain delay. This is because certain types of I/O failures (e.g. to high network congestion or packet drop rate) can take time to detect. Publishing can continue after the connection recovers.
Instead of retrying again and again to establish a connection, you can setup a Resource Alarm in rabbitmq. If the connection is blocked due to an alarm, all further attempts will fail until the alarm clears. Compatible AMQP 0-9-1 clients will be notified when they are blocked and unblocked.
Writes on a blocked connection will time out or fail with an I/O write exception.
-
-
An acknowledgement delivery timeout
- can only happen when the application developer provides a timeout. What timeout value is reasonable for a given application is decided by the developer. It should not be lower than the effective heartbeat timeout.
Metrics Collection and Monitoring for Publisher

Several metrics collected by RabbitMQ are of particular interest when it comes to publishers
-
Outgoing message rate
-
Publisher confirmation rate
-
Connection churn rate
-
Some applications open a new connection for every message published. This is highly inefficient and not how messaging protocols were designed to be used. Such condition can be detected using connection metrics.
Prefer long lived connections when possible.
-
-
Channel churn rate - Very important as they help detect applications that do not use connections or channels optimally and thus offer sub-optimal publishing rates and waste resources.
-
Unroutable dropped message rate
-
Unroutable returned message rate
Client libraries may also collect metrics. RabbitMQ Java client is one example. These metrics can provide insight into application-specific architecture (e.g. what publishing component publishes unroutable messages) that RabbitMQ nodes cannot infer.
Concurrency Considerations
Concurrency topics are all about client library implementation specifics but some general recommendations can be provided. In general, publishing on a shared "publishing context" (channel in AMQP 0-9-1, connection in STOMP, session in AMQP 1.0 and so on) should be avoided and considered unsafe.
Doing so can result in incorrect framing of data frames on the wire. That leads to connection closure.
With a small number of concurrent publishers in a single application using one thread (or similar) per publisher is the optimal solution. With a large number (say, hundreds or thousands), use a thread pool. If you share a channel among multiple threads, its possible they may try to publish on same channel leading to incorrect framing of data frames on the wire.
Note: Delivery tag is a 64 bit long value, and thus its maximum value is 9223372036854775807. Since delivery tags are scoped per channel, it is very unlikely that a publisher or consumer will run over this value in practice.
How to make system fully reliable? (in case you can’t afford message drops at all)
- Save messages to disk on rabbitmq server(permanent memory)
- Making exchange and queue durable, so that in case of server restart/shutdown, they still exist and do not get removed automatically
- Setting message
persistentparameter, in order to save message to disk
- Using Manual Acknowledgements in consumer
- Using Alternate Exchange
- Using Publisher Confirms or Transactional Channels
- Handle case if message is published multiple times or consumed multiple times, by making consumer task execution idempotent.
RabbitMQ Client Libraries and Developer Tools
https://www.rabbitmq.com/client-libraries/devtools
Best Practices
https://www.cloudamqp.com/blog/part1-rabbitmq-best-practice.html
https://www.cloudamqp.com/blog/part4-rabbitmq-13-common-errors.html
https://www.rabbitmq.com/docs/production-checklist
For more you can checkout the official documentation of RabbitMQ
References
https://www.cloudamqp.com/blog/what-is-amqp-and-why-is-it-used-in-rabbitmq.html
https://www.rabbitmq.com/confirms.html
https://www.rabbitmq.com/publishers.html